Q-learning 是人工智能领域的基本概念,特别是强化学习领域。它是一种无模型强化学习算法,旨在学习特定状态下动作的价值。Q 学习的最终目标是找到一个最优策略,定义在每个状态下采取的最佳行动,从而随着时间的推移最大化累积奖励。
了解 Q-Learning 基本概念:
Q-learning 基于 Q 函数的概念,也称为状态-动作值函数。该函数需要两个输入:状态和操作。它返回对预期总奖励的估计,从该状态开始,采取该行动,然后遵循最优策略。Q-Table:在简单的场景中,Q-learning 维护一个表(称为 Q-table),其中每行代表一个状态,每列代表一个操作。该表中的条目是 Q 值,随着代理通过探索和利用进行学习而更新。更新规则:Q学习的核心是更新规则,通常表示为: [ Q(s,a) leftarrow Q(s,a) + alpha r + gamma max_{a'} Q (s', a') - Q(s, a) ] 这里,( alpha ) 是学习率,( gamma ) 是折扣因子,( r ) 是奖励, ( s ) 是当前状态,( a ) 是当前动作,( s' ) 是新状态。(见下图)。
探索与利用:
Q-learning 的一个关键方面是平衡探索(尝试新事物)和利用(使用已知信息)。这通常通过 ε-贪婪等策略来管理,其中代理以概率 ε 进行随机探索,并以概率 1-ε 来利用最著名的操作。Q-学习和 AGI 之路 通用人工智能 (AGI) 是指人工智能系统理解、学习并将其智能应用于各种问题的能力,类似于人类智能。Q 学习虽然在特定领域很强大,但代表着向 AGI 迈出了一步,但有几个挑战需要克服: 可扩展性:传统的 Q 学习难以应对大型状态动作空间,这使得它无法解决 AGI 需要的现实世界问题处理。泛化:AGI 需要能够将学到的经验泛化到新的、未见过的场景。Q-learning 通常需要针对每个特定场景进行明确的训练。适应性:AGI必须能够动态适应不断变化的环境。Q 学习算法通常需要一个规则不随时间变化的固定环境。多种技能的整合:AGI意味着推理、解决问题和学习等各种认知技能的整合。Q-learning 主要关注学习方面,并将其与其他认知功能相结合是一个正在进行的研究领域。深度 Q 网络 (DQN) 的进展和未来方向:将 Q 学习与深度神经网络相结合,DQN 可以处理高维状态空间,使其更适合复杂任务。迁移学习:使在一个领域训练的 Q 学习模型能够将其知识应用到不同但相关的领域的技术可以是朝着 AGI 所需的泛化迈出的一步。元学习:在 Q 学习框架中实施元学习可以使 AI 学会如何学习,动态调整其学习策略——这是 AGI 的关键特征。Q-learning 是人工智能领域的一种重要方法,特别是在强化学习领域。毫不奇怪,OpenAI 使用 Q-learning RLHF 来尝试实现神秘的 AGI。
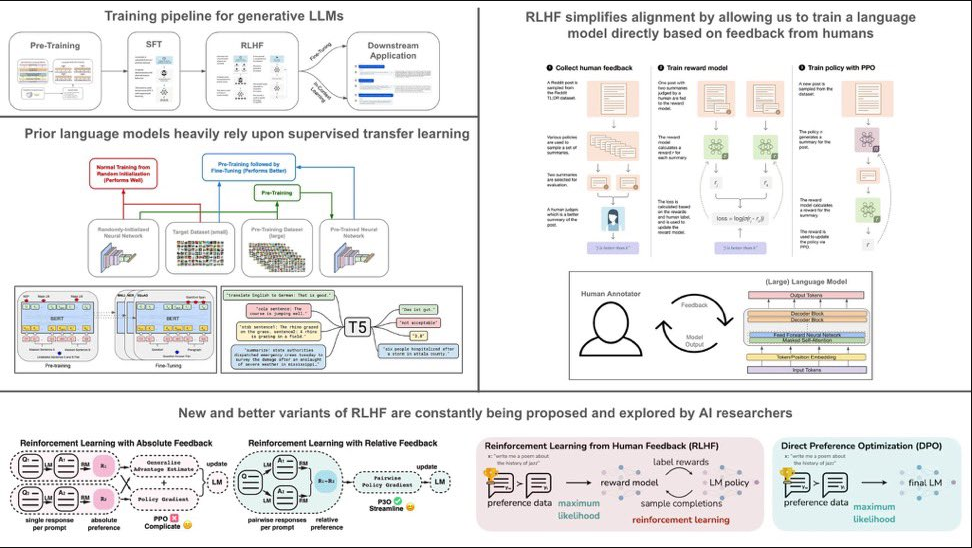
OpenAI 的秘密 Q* 使用的 RLHF 是什么?那么让我们来定义这个术语。RLHF 代表“根据人类反馈进行强化学习”。这是机器学习中使用的一种技术,其中模型(通常是人工智能)从人类给出的反馈中学习,而不是仅仅依赖于预定义的数据集。这种方法使人工智能能够适应更复杂、更细致的任务,而这些任务很难用传统的训练数据封装。在 RLHF 中,人工智能最初从标准数据集学习,然后根据人类反馈迭代改进其性能。反馈可以有多种形式,例如更正、不同输出的排名或直接指示。人工智能利用这种反馈来调整其算法并改进其响应或行动。这种方法在定义明确规则或提供详尽示例具有挑战性的领域特别有用,例如自然语言处理、复杂的决策任务或创造性的努力。这就是为什么 Q* 接受逻辑训练并最终适应简单算术的原因。随着时间的推移它会变得更好,但这不是 AGI。下图是 RLHF 的概述和历史